Meet the Kahneman Architecture: How Thinking, Fast and Slow Influenced the AI Analyst


When Daniel Kahneman passed away in 2024, the obituaries were unanimous: his book Thinking, Fast and Slow had changed how the world understood itself. It introduced everyone, from Silicon Valley product managers to politicians on the campaign trail, to a simple but powerful idea: the human mind runs on two operating systems.
System 1: fast, intuitive, automatic. It’s the snap judgment that tells you “that driver looks dangerous” before you consciously realize why.
System 2: slow, deliberate, reflective. It’s what you fire up when you’re doing your taxes or writing a wedding toast.
Once you see the split, you see it everywhere: in your impulse buys on Amazon (System 1) and in the pro-con list you make before accepting a new job (System 2).
And now, more than a decade later, it’s showing up somewhere new: in artificial intelligence.
Why Kahneman matters for machines
Most AI systems today are very sophisticated, and they’ve no doubt “read” Thinking, Fast and Slow, they haven’t really absorbed its lessons. They route every request, whether it’s “what day is today” or “predict churn by customer segment and revenue trend”, through the same giant model.
Humans don’t work this way. If someone asks you “what’s 2+2,” your brain doesn’t convene a committee. System 1 spits out the answer. If they ask you to calculate the future value of a loan with compound interest, that’s when System 2 rolls up its sleeves, reaches for pen and paper, and works it out step by step.
That human balance is what we’ve been working on at Rows for the new AI Analyst release. We’re calling it the Kahneman Architecture.
How the Kahneman Architecture works
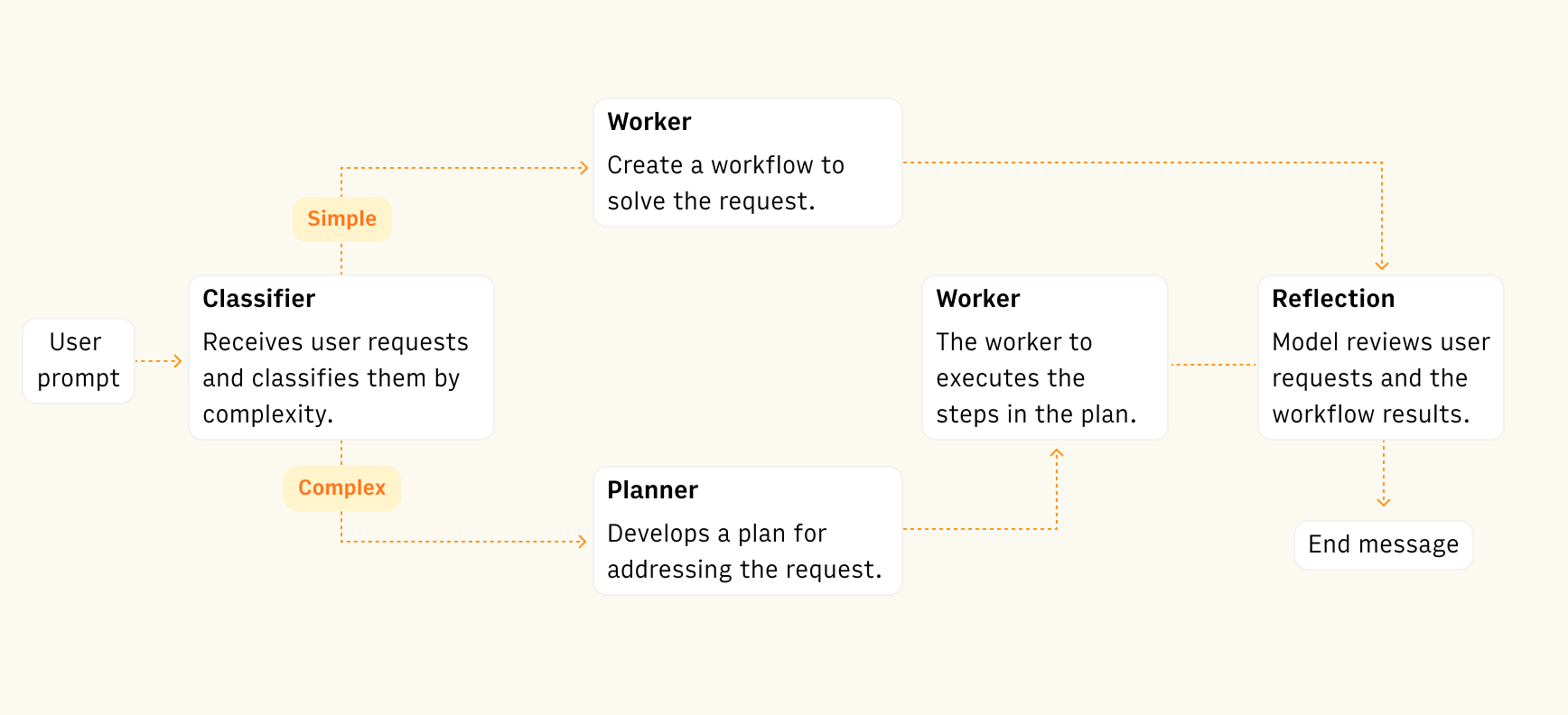 A simplified version of the AI Analyst architecture.
A simplified version of the AI Analyst architecture.Here’s how it plays out in practice, in the architecture (simplified) of the new AI Analyst.
The user sends a prompt. Let’s say: “Forecast revenue growth for next quarter.”
The classifier (intuition check). A small, fast inference model looks at the request and decides: is this simple or complex? It’s the AI equivalent of a gut check. It runs on an open-source model hosted by a fast inference engine and takes less than one second.
System 1: the fast path. If the task is classified as simple (“sum these numbers,” “sort by date”), it goes to a lightweight model that creates the workflow to complete the task. We don’t need a high-reasoning model here, so we use a model with minimal latency, like Gemini 2.5 Flash or GPT-5 with a lower reasoning parameter.
System 2: the slow path. If the task looks tricky the system escalates to a high-reasoning model. Instead of jumping straight to an answer, it builds a plan: breaking the job into smaller steps and handing each off to specialized “workers” that solve them one by one. This has three benefits:
It reduces the cognitive “load” any single worker has to carry, keeping execution closer to the original plan.
It increases speed overall, since each step can be handled by a faster, cheaper model.
It allows us to have dedicated high-reasoning workers who specialize on specific data analysis jobs, like creating complex reports from our data Integrations gallery from a plain language prompt (e.g. "Pull the my website visitors and conversions from last month and compare with the previous one.").
Reflection. Once the workers finish, there’s a reflection step. The AI reviews a snapshot of the spreadsheet state (including any errors), fixes issues, and only then confirms completion to the user. The reflection is a ensemble of several specialized workers:
one focused on styling and formatting.
one in the layout and composition of the spreadsheet.
and one one the fundamentals of building and fixing formulas, charts, python and other spreadsheet elements.
The result: speed when speed is possible, depth when depth is required, and a sanity check at the end.
And this is how the Kahneman Architecture maps psychology to computation:
System 1 → cheap inference. Snap judgments from small models, good enough for obvious cases.
System 2 → deliberate reasoning. Slower, more expensive, but capable of multi-step planning.
Reflection → meta-cognition. The part Kahneman always warned us about: intuition can be wrong, so check yourself.
It’s elegant and practical. Fast answers keep costs down and users happy. Slow answers ensure complex work gets done right. And reflection reduces the risk of hallucination and mistakes.
We can see the impact of the Kahneman Architecture in the end to end latency of the requests:
System 1 tasks take a median of 6s.
System 2 tasks take 69s.
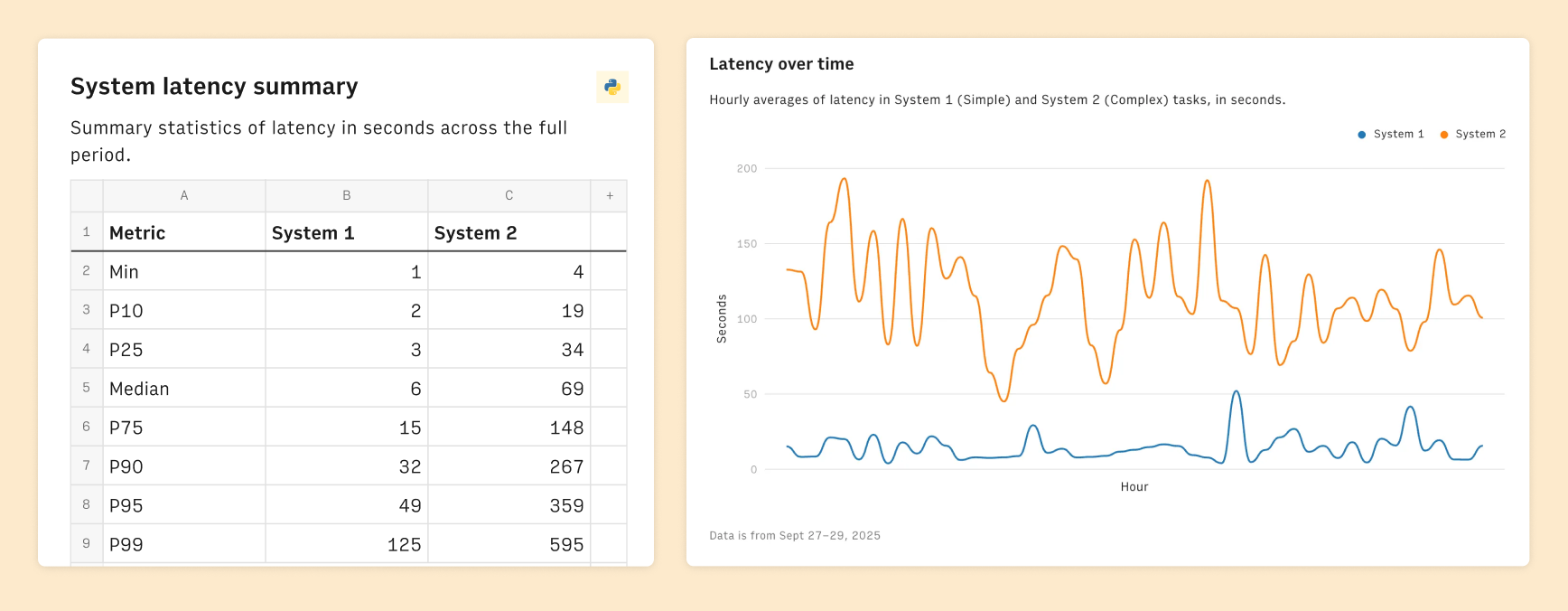 The latency difference between System 1 and System 2 tasks
The latency difference between System 1 and System 2 tasksAt a broader level, the idea of fast answers for simple tasks is under appreciated, but we believe it to be critical for the next generation of productivity software.
Think about it: if a spreadsheet user wants to format cells, add two numbers, or filter a column, the answer has to be instant. If it takes just a few seconds longer than doing it manually, people won’t bother. They won’t shift their habits. They won’t think “AI first.”
That’s a problem for users and for builders. If users avoid the AI for simple operations, they’ll use it a lot less, which means:
Product teams collect less usage data and feedback.
There are less opportunities for monetization.
Ultimately, the technology fails to reach its full potential.
A cultural moment
It’s not lost on anyone in AI that Thinking, Fast and Slow has become required reading in Silicon Valley. It sits on the same shelf as The Innovator’s Dilemma and The Lean Startup.
Now it’s giving us something else: a mental model for building AI products. One about orchestration, designing a system that knows when to trust a quick guess, when to think carefully, and when to double-check its own work.
Kahneman’s insight was that real intelligence isn’t about being fast or slow, but about balancing both. Because the future of AI will probably not be one giant, do-all model, but a system that feels, in its architecture, a little more like us: fast, slow, and smart enough to know the difference.

